Menu
Solving the Hallucination Problem: The Power of RAG and Local LLMs
Published on November 28, 2025
Solving the Hallucination Problem: The Power of RAG and Local LLMs
As AI systems become more capable, one major concern still slows down enterprise adoption: hallucinations. This is when large language models generate answers that sound confident, but aren’t actually true—or aren’t backed by any real source.
For industries like law, finance, healthcare, and government, even one wrong output can create serious legal, financial, or reputational risk. In these environments, accuracy isn’t a “nice to have”—it’s mandatory.
That’s exactly where Retrieval-Augmented Generation (RAG) and local LLM deployments make a real difference.
Data Sovereignty: Keeping Control of What Matters Most
A core requirement for enterprise AI is data sovereignty.
Organizations need to stay in control of:
- Where their data lives
- Who can access it
- How it’s processed
By running AI systems on-premise or inside a private cloud, companies reduce the risk of sensitive information leaving their infrastructure. Local LLMs also help ensure that internal documents, policies, and confidential records remain fully under the organization’s control.
This matters even more in regulated industries, where compliance rules and internal governance policies leave very little room for uncertainty.
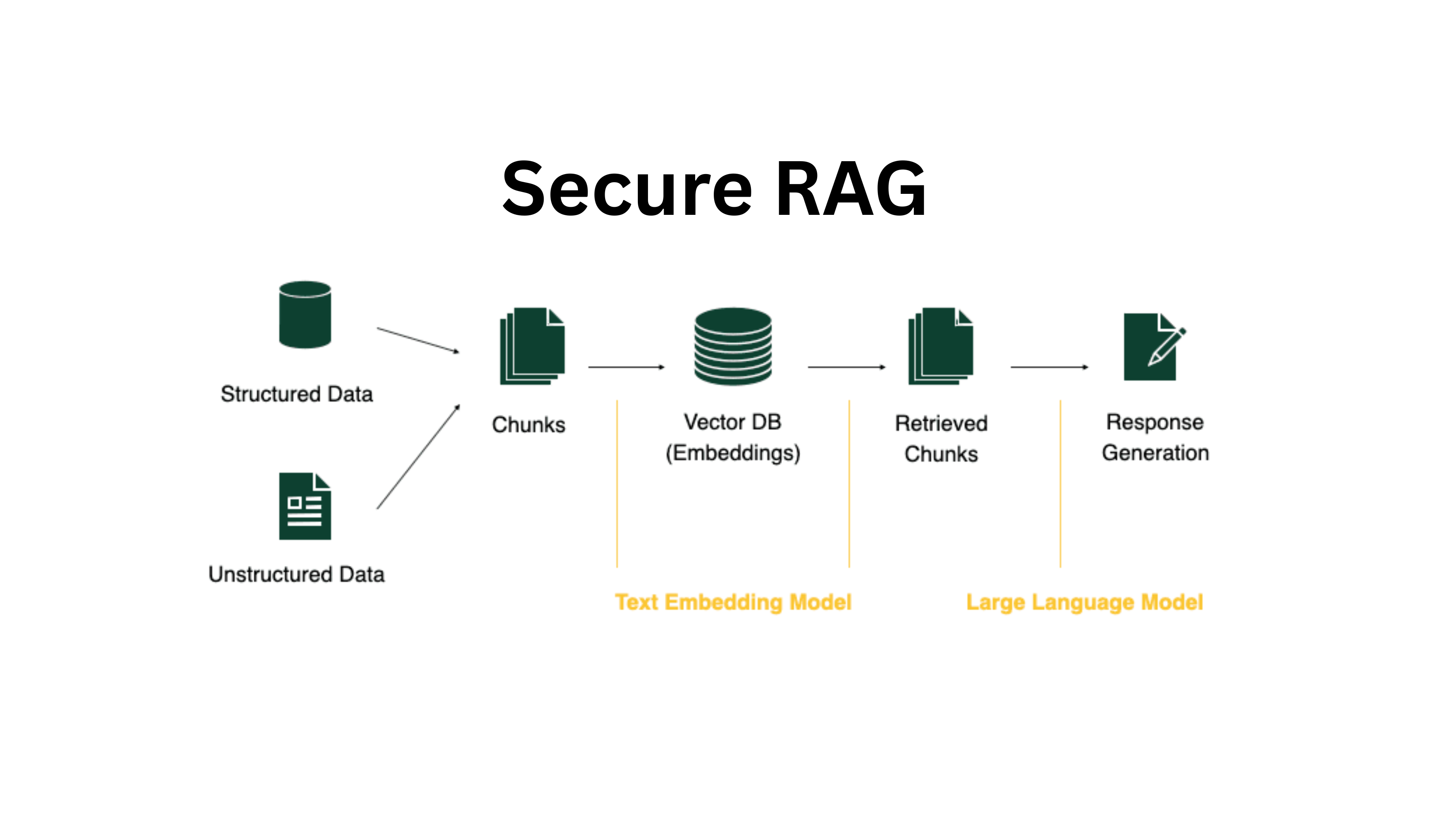
RAG Architecture: Grounding AI in Reality
Retrieval-Augmented Generation tackles hallucinations at the source.
Instead of relying only on what a model “remembers,” a RAG system works like this:
- It retrieves the most relevant information from trusted internal documents
- It injects that content directly into the model’s context
- It generates an answer based on those sources
The output becomes grounded in real, verifiable data.
And if the information doesn’t exist in the knowledge base, the system shouldn’t guess or make something up.
This turns LLMs from creative text generators into reliable enterprise knowledge workers.
Dual-Layer Verification: Trust, but Verify
At AIME, we take reliability a step further with dual-layer verification.
In this setup:
- A primary model generates a response using RAG
- A secondary model reviews and validates the output
- Unsupported claims, missing references, or inconsistencies are flagged automatically
This extra layer makes the final result far more dependable and reduces the chances of misinformation reaching end users.
In practice, it behaves less like a chatbot—and more like a disciplined analyst that checks its own work.
Secure AI Is Not Optional
Security should never be treated as an afterthought in AI design.
By combining:
- Local data sources
- Isolated execution environments
- RAG-based grounding
- Multi-model verification
Organizations can confidently use large language models without sacrificing data privacy or factual accuracy.
At AIME, we build AI ecosystems where trust, accuracy, and security are built-in from day one—not added later. That’s how teams can adopt AI at scale while still meeting enterprise-level compliance and security standards.